
tl;dr
1. Despite the absence of semantic labels in the training data, SAM implies high-level semantics sufficient for captioning.
2. SCA (b) is a lightweight augmentation of SAM (a) with
the ability to generate regional captions.
3. On top of SAM architecture, we add a fixed pre-trained language model, and
an optimizable lightweight hybrid feature mixture whose training is cheap and scalable.
News
- [01/31/2024] Update the paper and the supp. Release code v0.0.2: bump transformers to 4.36.2, support mistral series, phi-2, zephyr; add experiments about SAM+Image Captioner+V-CoT, and more.
- [12/05/2023] Release paper, code v0.0.1, and project page!
Abstract
We propose a method to efficiently equip the Segment Anything Model (SAM) with the ability to generate regional captions. SAM presents strong generalizability to segment anything while is short for semantic understanding. By introducing a lightweight query-based feature mixer, we align the region-specific features with the embedding space of language models for later caption generation. As the number of trainable parameters is small (typically in the order of tens of millions), it costs less computation, less memory usage, and less communication bandwidth, resulting in both fast and scalable training. To address the scarcity problem of regional caption data, we propose to first pre-train our model on objection detection and segmentation tasks. We call this step weak supervision pretraining since the pretraining data only contains category names instead of full-sentence descriptions. The weak supervision pretraining allows us to leverage many publicly available object detection and segmentation datasets. We conduct extensive experiments to demonstrate the superiority of our method and validate each design choice. This work serves as a stepping stone towards scaling up regional captioning data and sheds light on exploring efficient ways to augment SAM with regional semantics.
SCA Design
SCA is a training-efficient and scalable regional captioning model with a lightweight (typically in the order of tens of millions) query-based feature mixer that bridges SAM with causal language models.
- The model consists of three main components: an image encoder, a feature mixer, and decoder heads for masks or text.
- The text feature mixer, a lightweight bidirectional transformer, is the crucial element of the model.
- We leverage the tokens from SAM and stack the new mixer above it.
- By optimizing only the additional mixer, the region-specific features are aligned with the language embedding space.
- Due to the small amount of optimizable parameters, the training process is both efficient and scalable.
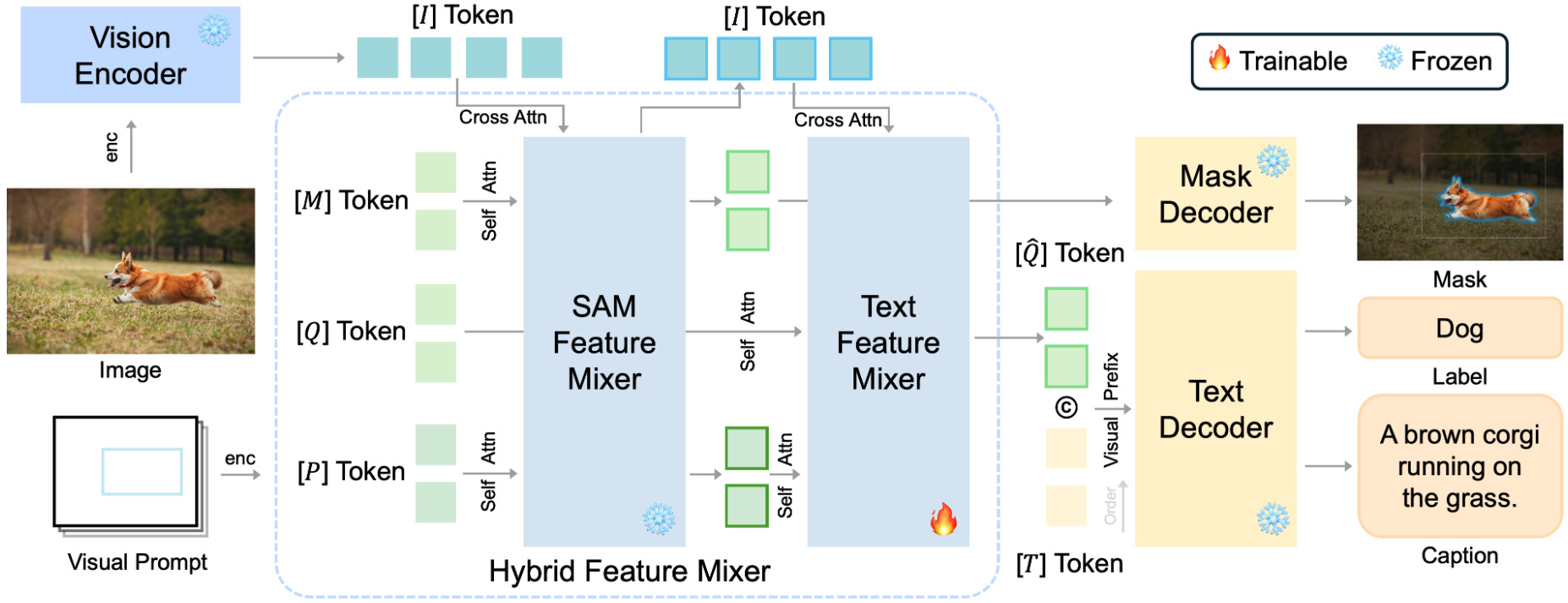
The model architecture of SCA.
Performance
We conducted extensive experiments to validate the effectiveness of SCA. More results and ablations can be found in our paper.
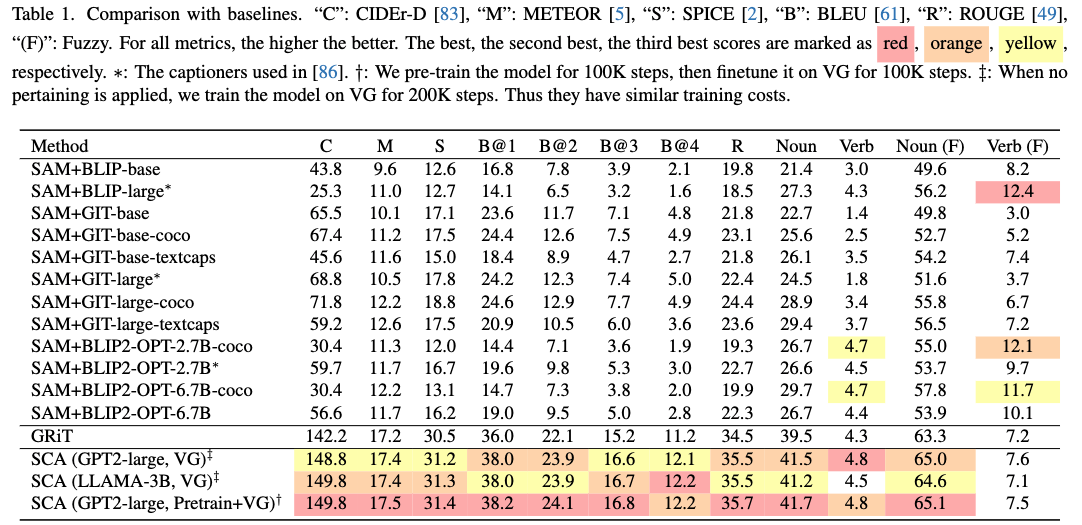
Compare with baselines.
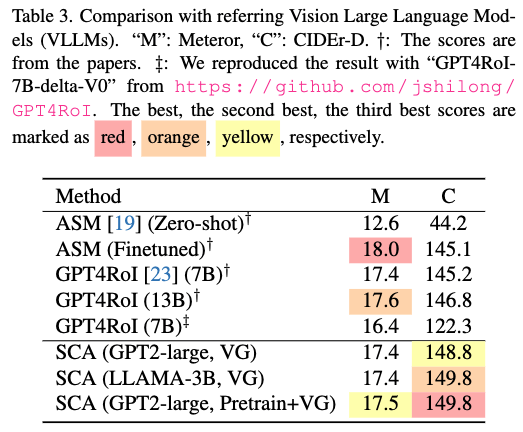
Compare different referring Vision Large Language Models (VLLMs).
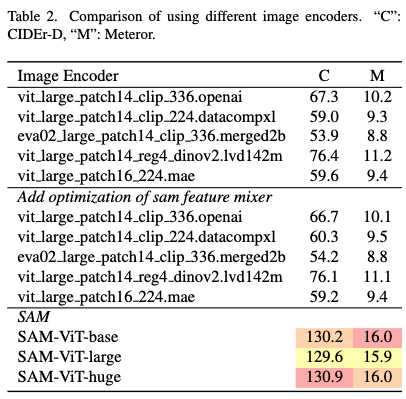
Compare different image encoders.
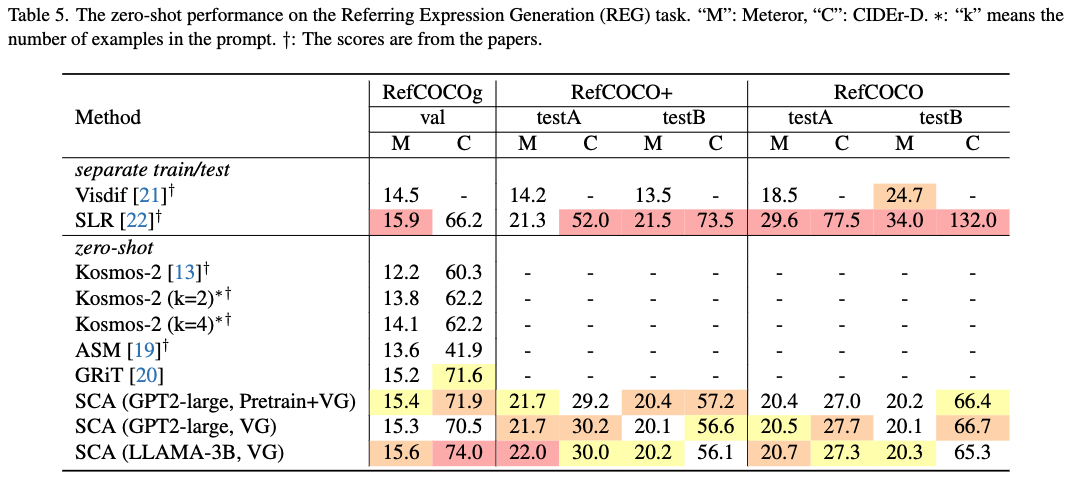
Zero-shot performance on Referring Expression Generation (REG) task.
Visualization
The qualitative results. SCA simultaneously predicts masks (in red contour) and captions. From top-to-bottom, the captions are from: (1) SAM+Captioner {GIT-large, BLIP-large, BLIP2-OPT-2.7B}, (2) GRIT [89], (3) SCA {GPT2-large+VG, LLAMA-3B+VG, GPT2- large+Pretrain+VG}, and (4) the ground truth. The bounding boxes (in red) are used to prompt the models. Click for a zoom-in view.









We provide more examples in our supplementary material.
Demo
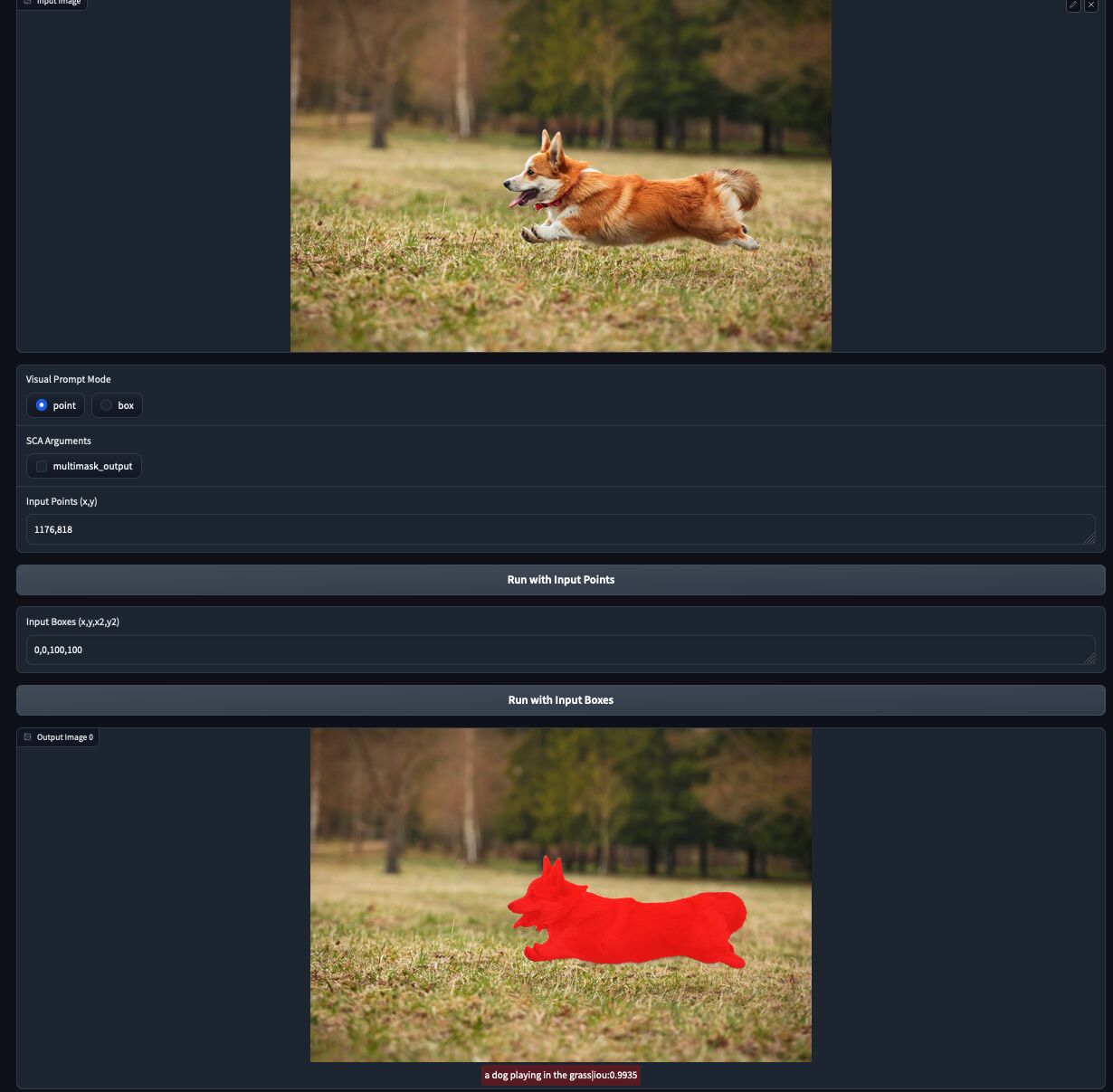
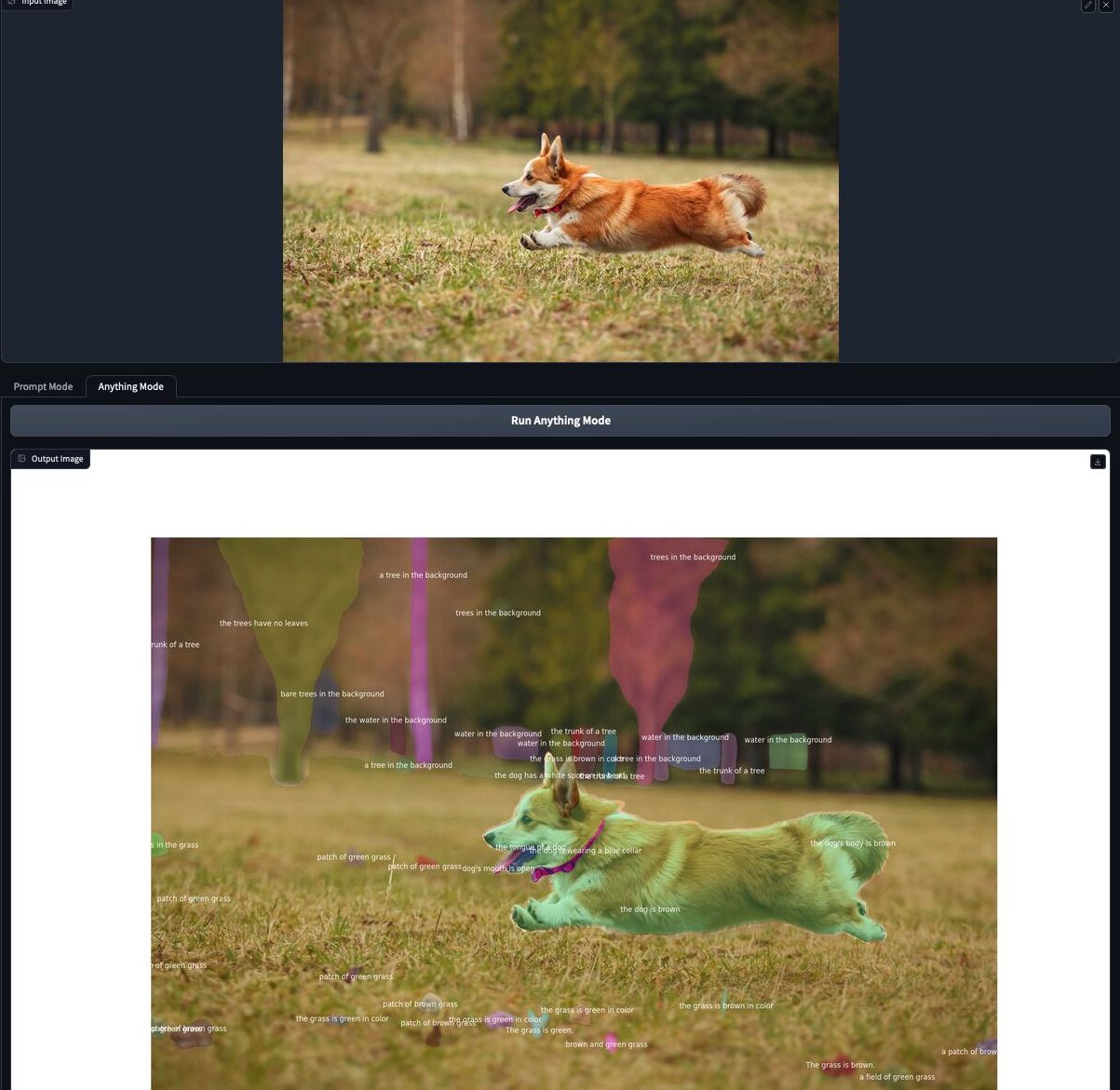
We provide a gradio demo for SCA with both "prompt mode" and "anything mode" in Gradio Demo. Click for a zoom-in view.




Conclusions and Discussion
We have demonstrated a scalable regional captioning system leveraging the SAM segmentation model and a lightweight feature mixer, pre-trained with weak supervision for enhanced generalization. Despite some limitations, the system shows strong performance and potential for future development.
- Utilized SAM, a class-agnostic segmentation model, in combination with a lightweight query-based feature mixer to develop a regional captioning system. The system was pre-trained with weak supervision, using 1.8M data, to transfer visual concepts beyond limited regional captioning data.
- Our design choices have been extensively validated and evaluated, demonstrating strong performance. Ablation studies showed that the scale of images matters more than the variety of labels for the effectiveness of weak supervision. Leveraging bigger datasets or image captioning data can potentially improve the generalizability of the model.
- The system has limitations, including wrong attribute prediction, distinguishing similar visual concepts, and alignment with mask predictions. The issues may be addressed by weak supervision and self-training. The ultimate goal is self-training, which could scale both the data and the generalizability of the model.
- Despite the absence of semantic labels in the training data, SAM implies high-level semantics sufficient for captioning. We believe this work serves as a stepping stone towards scaling regional captioning data and exploring emerging abilities in vision from low-level data or pre-trains.
BibTeX
@inproceedings{huang2024segment,
title={Segment and caption anything},
author={Huang, Xiaoke and Wang, Jianfeng and Tang, Yansong and Zhang, Zheng and Hu, Han and Lu, Jiwen and Wang, Lijuan and Liu, Zicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13405--13417},
year={2024}
}
}Acknowledgement
We thank Yutong Lin, Yiji Cheng and Jingcheng Hu for their generously support and valuable suggestions.
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.