EMA: Efficient Meshy Neural Fields
for Animatable Human Avatars
EMA efficiently and jointly learns canonical shapes, materials, and motions via differentiable inverse rendering in an end-to-end manner. The method does not require any predefined templates or riggings. The derived avatars are animatable and can be directly applied to the graphics renderer and downstream tasks.
Abstract
Efficiently digitizing high-fidelity animatable human avatars from videos is a challenging and active research topic. Recent volume rendering-based neural representations open a new way for human digitization with their friendly usability and photo-realistic reconstruction quality. However, they are inefficient for long optimization times and slow inference speed; their implicit nature results in entangled geometry, materials, and dynamics of humans, which are hard to edit afterward. Such drawbacks prevent their direct applicability to downstream applications, especially the prominent rasterization-based graphic ones. We present EMA, a method that Efficiently learns Meshy neural fields to reconstruct animatable human Avatars. It jointly optimizes explicit triangular canonical mesh, spatial-varying material, and motion dynamics, via inverse rendering in an end-to-end fashion. Each above component is derived from separate neural fields, relaxing the requirement of a template, or rigging. The mesh representation is highly compatible with the efficient rasterization-based renderer, thus our method only takes about an hour of training and can render in real-time. Moreover, only minutes of optimization is enough for plausible reconstruction results. The disentanglement of meshes enables direct downstream applications. Extensive experiments illustrate the very competitive performance and significant speed boost against previous methods. We also showcase applications including novel pose synthesis, material editing, and relighting.
Video
Method
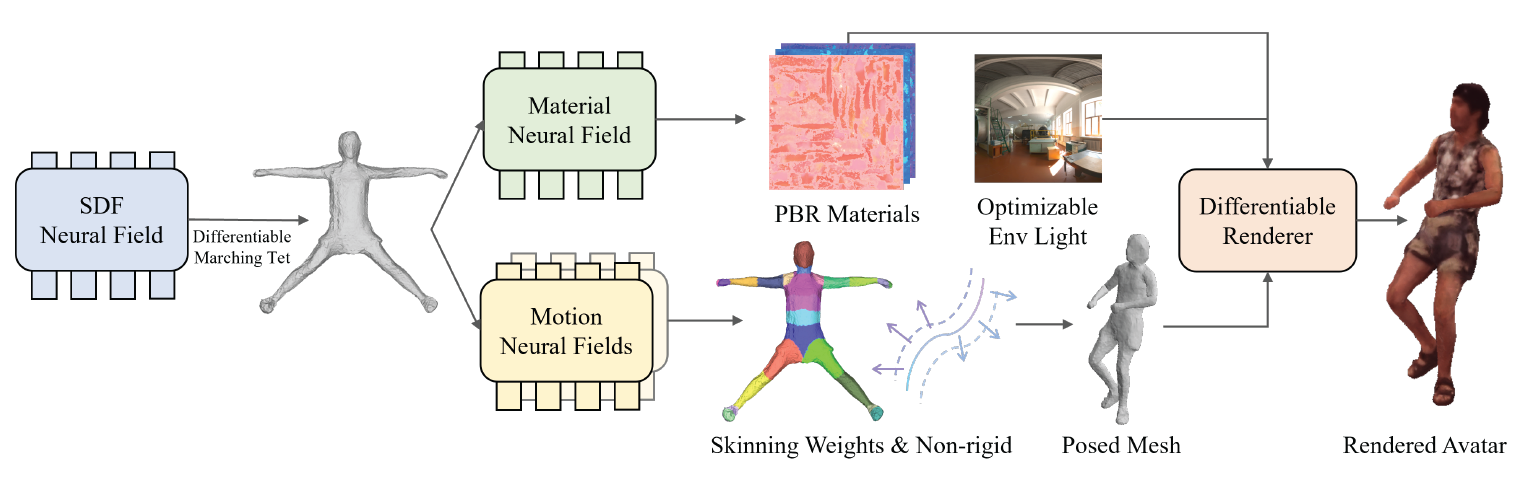
The pipeline of EMA. EMA jointly optimizes canonical shapes, materials, lights, and motions via efficient differentiable inverse rendering. The canonical shapes are attained firstly through the differentiable marching tetrahedra, which converts SDF fields into meshes. Next, it queries PBR materials, including diffuse colors, roughness, and specularity on the mesh surface. Meanwhile, the skinning weights and per-vertices offsets are predicted on the surface as well, which are then applied to the canonical meshes with the guide of input skeletons. Finally, a rasterization-based differentiable renderer takes in the posed meshes, materials, and environment lights, and renders the final avatars efficiently.
Training Efficiency
ZJU-MoCap 313 subject. With minutes of training, our method can produce indicative results.
Qualitative Comparisons
ZJU-MoCap 313 subject. Only the first 60 frames (~2 sec) are used for training, yet the rest frames are left for testing. Thus the motions in the training data are quite limited, which challenge the generalization ability.
Representation Visualization
We visualize the rendering, albedo, materials, and normals for each subject. The disentangled mesh and material representations enable us instant editing in downstream tasks once the training is finished.
Novel Pose Synthesis on AIST
Since we model the canonical shapes and the forward skinning, we can easily synthesize humans with novel poses (e.g. poses from the AIST dataset).
Texture Editing and Relighting
Here we showcase downstream applications, such as texture editing and relighting.
Citation
Acknowledgements
We would like to give very special thanks to Jinpeng Liu for the video editing. We would like to thank Yunzhi Teng for the constructive discussions. The website template was borrowed from Michaël Gharbi and Jon Barron.